
Tomato Basil
FMA-Net | 논문리뷰 (2) 본문
1편에서는 전체적인 FMA-Net의 구조를 다루었는데, 이번 2편에서는 구성 요소에 대해 다룹니다.
FMA-Net | 논문리뷰 (1)
[FMA-Net] FMA-Net은 Super Resolution + Deblurring 을 통해 저화질 영상을 고화질로 만들어주는 모델입니다.모델 구조를 이해하고, pre-trained 모델을 돌려볼 예정입니다. FMA-Net: Flow-Guided Dynamic Filtering
tomato-basil.tistory.com
<recap - 두 가지 네트워크>
$Net^D$ : degradation learning network
motion-award spatio-temporally-variant degradation kernels를 예측
$Net^R$ : resotration network
예측된 degradation kernels을 활용하여 흐릿한 저화질 영상을 복원
1. FRMA 블럭
$Net^D$와 $Net^R$ 은 공통점을 가집니다.
바로 FRMA 블럭들이 스택되어 있고, FGDF 모듈을 가진다는 것입니다.
우선 흐린 영상에서는 이미지, 특징을 기반으로 한 optical flow 정보를 이용하여 motion 정보를 파악하고, 이를 디블러링할 때 적용합니다. 하지만 디블러링에 pre-train된 optical flow network를 바로 적용하는 것은 안정적이지 않으며, 연산이 비싸기도 합니다. 따라서 FMA-Net에서는 FRMA 블럭들을 스택하는 방식을 택했습니다.
FRMA 블럭이란?
FRMA block is designed to learn self-induced optical flow and features in a residual learning manner
M개의 FRMA 블럭을 거치며 특징이 반복적으로 정제됩니다. FRMA 블럭들은 occlusion mask와 함께 여러 optical flow들을 학습합니다. 다양한 optical flow를 학습하기 때문에, 한 프레임과 이웃하는 프레임 간의 관계를 더 잘 파악할 수 있습니다. 따라서 픽셀 정보가 잘 수집되지 않는 흐릿한 영상에 적용하기 좋은 기법입니다.
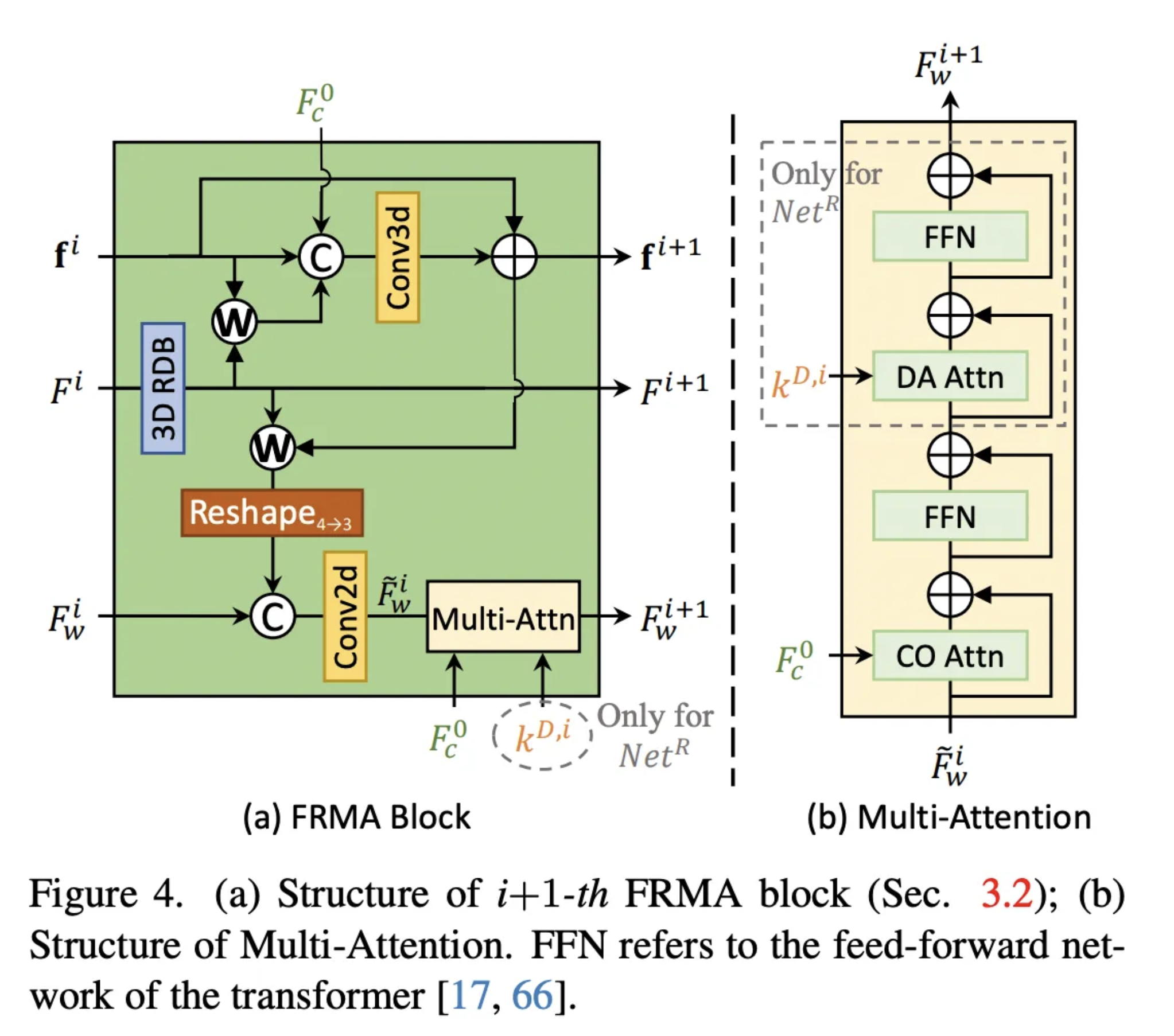
Figure.4는 (i+1)번째 update-step에서의 FRMA 블록 구조를 보여주고 있습니다.
앞으로는 구분이 필요할 경우, $Net^D$의 FRMA 블럭을 $FRMA^D$, 그리고 $Net^R$ 의 FRMA 블럭을 $FRMA^R$ 로 표기하겠습니다.
FRMA 블럭은 다음 세 가지의 tensor를 정제합니다.
- \( F \): 각 프레임 인덱스에서의 temporally-anchored (unwarped) feature \( F \in \mathbb{R}^{T \times H \times W \times C} \)
- \( F_w \): warped feature \( F_w \in \mathbb{R}^{H \times W \times C} \)
- \( f \): multi-flow-mask pairs \[\mathbf{f} \equiv \left\{ f^{j}_{c \rightarrow (c+t)}, o^{j}_{c \rightarrow (c+t)} \right\}^{j=1:n, t=-N:N} \in \mathbb{R}^{T \times H \times W \times (2+1)n}\] 여기서 \( n \)은 중심 프레임 인덱스 \( c \)에서 각 프레임 인덱스로의 multi-flow-mask pair의 개수를 나타냅니다. 이때 learnable occlusion mask \( o^{j}_{c \rightarrow (c+t)} \)는 안정성을 위해 sigmoid activation을 사용합니다.
(i) 번째 update-step에서 얻은 $F$ , $f$ , $F_w$ 순으로 업데이트됩니다.
- 먼저 $F^i$를 3D RDB 를 통해 정제시켜 $F^{i+1}$를 얻어냅니다.
$F_{i+1} = RDB(Fi)$ - 얻은 $F_{i+1}$ 를 $f^i$를 기반으로 center frame index $c$ 로 warping 합니다.
그리고 그 결과를 다음과 같이 concatenation 해줍니다.
${f}^{i+1} = {f}^i + {Conv}_{3d}({concat}(\textbf{f}^i, \mathcal{W}(F^{i+1}, \textbf{f}^i), F_c^0))$
$W$는 occlusion-aware backward warping,
$concat$은 channel dimension 기반 concatenation 입니다.
$F_c^0$은 가장 최초의 프레임의 center frame index $c$의 feature map 입니다. - 마지막으로, warp된 $F^{i+1}$, $f^{i+1}$를 이용하여 다음과 같이 $F_w^i$를 업데이트합니다.
${F}w^i = {Conv}{2d}({concat}(F_w^i, r_{4 \rightarrow 3}(\mathcal{W}(F^{i+1}, \textbf{f}^{i+1}))))$
이때 $r_{4 \rightarrow 3}$ 는 ${R}^{T \times H \times W \times C}$에서 ${R}^{H \times W \times TC}$로 feature aggregation을 위한 reshape 연산입니다.
2. FGDF(flow-guided dynamic filtering)
우선 동적 필터링(dynamic filtering)에 대해서 간단히 짚고 넘어가겠습니다.
$y(p) = \sum_{k=1}^{n^2} F^p(p_k) \cdot x(p+p_k)$
이미지에서는 위와 같이 포지션 $p$에서의 nxn dynamic filter 를 $F^p$ 라고 하고,
$x$와 $y$를 각각 인풋, 아웃풋이라고 할 수 있습니다.
$p^k$는 nxn 크기의 k번째 sampling offset 를 의미합니다.
만약 비디오라면,
$y(p) = \sum_{t=-N}^{+N}\sum_{k=1}^{n^2} F^p_{c+t}(p_k) \cdot x_{c+t}(p+p_k$
인풋 프레임의 center frame index를 의미하는 $c$ 와 함께 이렇게 표현될 수가 있을 것입니다.
하지만, 픽셀의 위치(주변 포함)를 고정한다면 보다 큰 motion을 감지하기 위해서는 아주 큰 필터가 필요할 것입니다. 컴퓨터 연산과 메모리 사용도 늘어날 것입니다. 따라서 FMA-Net에서는 DCN으로부터 영감을 받아 FGDF(flow-guided dynamic filtering)을 제안하고 있습니다. 각 커널은 optical flow의 움직임을 따라 동적으로 생성되며 pixel-wise motion-aware 합니다. 덕분에 보다 작은 크기의 커널로 큰 모션을 감지할 수 있게 되었습니다.
$y(p) = \sum_{t=-N}^{+N}\sum_{k=1}^{n^2} F^p_{c+t}(p_k) \cdot x'_{c+t}(p+p_k)$
FGDF 수식은 위와 같습니다.
$x^{\prime}_{c+t} = W(x{c+t}, f_{c+t})$ 와 $f_{c+t}$ 는
c 및 c+t frame index 에서의 optical flow + occlusion mask를 의미합니다.
3. 사전 훈련된 모델 테스트 해보기
GitHub - KAIST-VICLab/FMA-Net: [CVPR 2024 Oral] Official repository of FMA-Net
GitHub - KAIST-VICLab/FMA-Net: [CVPR 2024 Oral] Official repository of FMA-Net
[CVPR 2024 Oral] Official repository of FMA-Net. Contribute to KAIST-VICLab/FMA-Net development by creating an account on GitHub.
github.com
깃허브에서 pre-trained 모델 폴더를 받아서 colab을 돌려보았습니다.
conda - REDS 데이터셋 메모리 초과로 실행 불가

REDS 데이터셋은 각 영상이 99개의 이미지로 담겨있었는데, 각 이미지 파일 크기가 1MB 합니다.
test를 하려고 코드를 돌려보았는데, 메모리 초과가 떠서 다른 방법을 구해봐야겠다고 생각이 들었습니다. 혹은 제가 정확한 방법을 몰랐을 것이라고 추측됩니다. FMA-Net 폴더 안에 전처리 파일이 있는데, 이 전처리 파일을 제가 직접 실행해서 인풋 데이터를 전처리 시켜주어야 하는 것인지, 아니면 FMA-Net의 main.py, model.py, data.py 등이 대신 일을 해주는지 확인해봐야할 것 같습니다.
experiment.cfg 파일

우선은 메모리 초과 문제를 배제하고 모델이 인풋 → 아웃풋을 만들어내는지 여부를 알아보기 위해 제가 가지고 있던 사진 4장을 인풋으로 넣어보았습니다. 그 경로를 experiment.cfg 파일의 제일 하단에 있는 custom_path에 할당해주었습니다. (003 폴더)
전처리 모델 .pt

FMA-Net/reseults 폴더 안에는 원래 model_stage2 폴더가 있습니다. 이 폴더 안에 pre-trained model인 model_D_best.pt, model_R_best.pt를 넣어주었습니다.
FMA-Net/test 폴더는 FMA-Net의 아웃풋이 저장되는 경로입니다.
이미지 인풋, 아웃풋

상단 이미지 4장이 제가 인풋으로 넣은 이미지 4장입니다. 100x66 사이즈입니다.
하단 이미지 2장이 아웃풋으로 나온 이미지로, 400x264 사이즈 입니다. (노션에 넣은 후 캡쳐한 것이라 비율이 유지되진 않았습니다)
크기가 4배가 되었고, 이미지의 질이 향상되었음을 확인할 수 있습니다.
'AI > CV' 카테고리의 다른 글
| FMA-Net | 논문리뷰 (1) (0) | 2024.06.06 |
|---|
